
Buena parte de mi carrera como químico en la industria ha estado
ligada a la aplicación de polímeros sobre superficies metálicas
para distintos usos, desde envases alimentarios hasta recubrimientos
hidrofílicos en aletas de intercambiadores de calor, pasando por
blísters farmacéuticos. Cuando queríamos conseguir propiedades
mecánicas importantes, como la capacidad de los polímeros de
resistir una fuerte deformación del metal, o químicas, como
resistencia a la corrosión o medios ácidos, sabíamos que la clave
era estabilizar la estructura tridimensional de los polímeros
consiguiendo que las distintas macromoléculas poliméricas creasen
enlaces estables entre sí. Es lo que se llama curado, en términos
del oficio, o reticulación, poniéndonos un poco más técnicos, ya
que se crea una red tridimensional.
El amable lector se preguntará a qué viene esto. Pues viene a
que la noticia que comento a continuación es de esas que pasan
inadvertidas, de las que poca gente sabe apreciar, y que sin embargo
entrañan una dificultad técnica notable y tienen una transcendencia
económica a futuro innegable. Espero ser capaz de explicarla como
merece, en este caso particular corro el riesgo de emplear demasiada
jerga. Vamos a ello.
Un equipo de investigadores, encabezado por Gaetano Distefano, de
la Universidad de Milán-Bicocca (Italia), ha creado un material de
base polimérica que tiene estructura cristalina. El material
consigue su cristalinidad con entrecruzamientos entre cadenas
poliméricas. Los resultados se publican en Nature Chemistry.
La estructura de los materiales compuestos por fibras, como son
las cadenas de polímeros, tiene un gran impacto en sus propiedades.
Un caso conocido es el Kevlar, que consigue su alta tensión de
rotura (ideal para chalecos antibalas o velas náuticas de
competición) porque los polímeros se alinean creando entre ellos
multitud de puentes de hidrógeno. Por esta razón los químicos han
(en este caso, hemos) empleado mucho tiempo y esfuerzo en conseguir
estructuras tridimensionales estables y regulares de distintos
polímeros o, en una palabra, que se aproximasen a una forma
cristalina.
Las técnicas para conseguir una estructura tridimensional estable
de un haz de fibras varían mucho con el polímero en cuestión.
Desde puramente mecánicas, como el “peinado”, en el que las
fibras se alinean simplemente frotando la superficie en la que están
depositadas [por si alguien conoce los maquinones donde esto se hace,
aquí tiene una explicación de por qué tienen tal cantidad de
rodillos de paso no motorizados]. Los polímeros pi-conjugados, esos
en los que los electrones están compartidos por muchos átomos y sus
enlaces, se alinean “químicamente”, empleando moléculas guía
[realmente es una acción puramente electrostática en esta fase,
pero bueno]. Estos métodos como se puede intuir son muy específicos
de cada polímero o mezcla de polímeros, y son simplemente
alineaminetos, como conseguir que un montón de espaguetis estén en
la misma dirección en una mesa. El alineamiento, siendo una
condición necesaria pero no suficiente, por sí solo no garantiza ni
resistencia al calor ni a los disolventes.
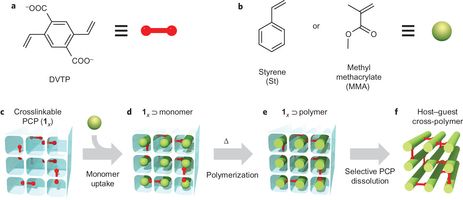
Lo que este grupo de investigadores ha hecho viene a ser lo
siguiente, usando un símil de la edificación: imaginar el producto
final, crear un andamio que diese su estructura general, incorporar
los anclajes de la estructura, y subir los ladrillos al andamio;
después han creado los muros con los ladrillos, los han sujetado con
los anclajes cada uno en su sitio y han retirado los andamios,
quedando la estructura buscada. El andamio se llama PCP (polímero de
coordinación poroso). En esta estructura dada por el PCP Distefano
et al. embebieron moléculas de DVTP (2,5-divinil-tereftalato), que
actuarían como anclajes, entrecruzándose (formando enlaces con
distintas cadenas) con el polímero. Después incorporaron a la
estructura los ladrillos, monómeros de etenilbenceno (estireno para
los amigos), en los canales paralelos de la PCP. Con todo en su sitio
polimerizaron los monómeros, obteniendo poliestireno, a la vez que
se entrecruzaba. Finalmente retiraron el andamio disolviendo el PCP
con EDTA (ácido etilen-diamino-tetra-acético). Resultado:
poliestireno cristalino (no se confunda con poliestireno cristal, que
es un grado industrial).
Para saber si se ha logrado el objetivo
desde un punto de vista macroscópico tan sólo hay que medir la
densidad conseguida y comprobar la resistencia a calor y disolventes.
A mejor empaquetamiento, mejor ocupación del espacio, más densidad.
El nuevo material tiene una densidad de 1,13 g/cm3,
alrededor de un 8% más que el poliestireno normal (el que se emplea
en los envases de yogur, por ejemplo) que es de 1,05 g/cm3,
buena señal. Además aguanta los disolventes orgánicos habituales y
temperaturas de hasta 200 ºC. Espectacular. Eso sí, serán
necesarias muestras mayores que las obtenidas para poder determinar
las propiedades mecánicas de interés ingenieril.
Tenemos que hacer constar que en las veriones habituales del poliestireno, atáctico y sindiotáctico, se habla siempre de grados de cristalinidad, lo que indica el nivel de ordenamiento. No son cristales reales, aparte de por no estar completamente ordenados microscópicamente, porque macroscópicamente no tienen una temperatura de fusión, sino una temperatura de transición vítrea. Por otra parte la estructura cristalina del poliestireno isotáctico fue determinada por Giulio Natta en 1960.
Este trabajo es un ejemplo magnífico de todo el campo que queda
por explorar en el uso de polímeros convencionales desde el punto de
vista estructural, materiales, no lo olvidemos, completamente
orgánicos.
Esta entrada es una participación
de Experientia docet en
la XXII Edición del Carnaval de Química que
organiza Roskiencia
Referencia:








